


第一回目となる前回の記事では、人工知能の概要と歴史、そして発展した要因と社会的なニーズについて述べた。今回の記事では、AIの特に機械学習やDeep Learningにおける概念的な説明を行う。
汎用人工知能と特化型人工知能
AIという言葉を聞いたときに、SF映画などに登場するような「人間のように自律的に、かつ分野を横断して柔軟に思考・決定・行動をする」といったコンピュータシステムを思い浮かべる方も多いのではないだろうか。鉄腕アトムやドラえもんなどもそのような類の一つである。
これらは、「汎用人工知能」と呼ばれるもので、AIというものを最も大きな軸で分類しようとした際の方法の一つである。「汎用人工知能」が実現し、人間の知能を超えるシンギュラリティ(技術的特異点)が訪れるという予測をしている学者もおり、実現に向けて研究を進めている。
AIを大きな軸で分類する際のもう一つが「特化型人工知能」と呼ばれるもので、これは「個別の課題やタスクに特化して能力を発揮する」ものである。現在スマートフォンで使われているSiriなどの音声認識システムや、Googleの子会社であるDeep Mindが開発し、韓国のプロ囲碁棋士「李世乭」を破った囲碁プログラムである「AlphaGo」などはその代表例である。
「データから学習する」とは何か
このように、AIは汎用人工知能と特化型人工知能の二つに分類することができるが、2018年現在、ビジネスや現実世界で実現できているのは特化型人工知能である。
特化型人工知能の分野で、現在特に活発にビジネスへの応用が進められているのが、機械学習・Deep Learningである。これらは「特定の問題を解けるように、データから学習する」といったものである。

データから学習するアプローチ方法は、データの与え方や問題設定に応じて様々だ。そのうちの一つが「教師あり学習」と呼ばれるものである。
教師あり学習では、AIに入力データと、そのデータから導き出すべき答えである目標ラベルをセットで与える。この入力データと目標ラベルのセットを「教師データ」と呼ぶ。例えば、顔から性別を予測する問題の場合、入力データとして人の顔写真を与え、答えとなるラベルとして男性や女性といった情報をセットで与える、といったようなものである。
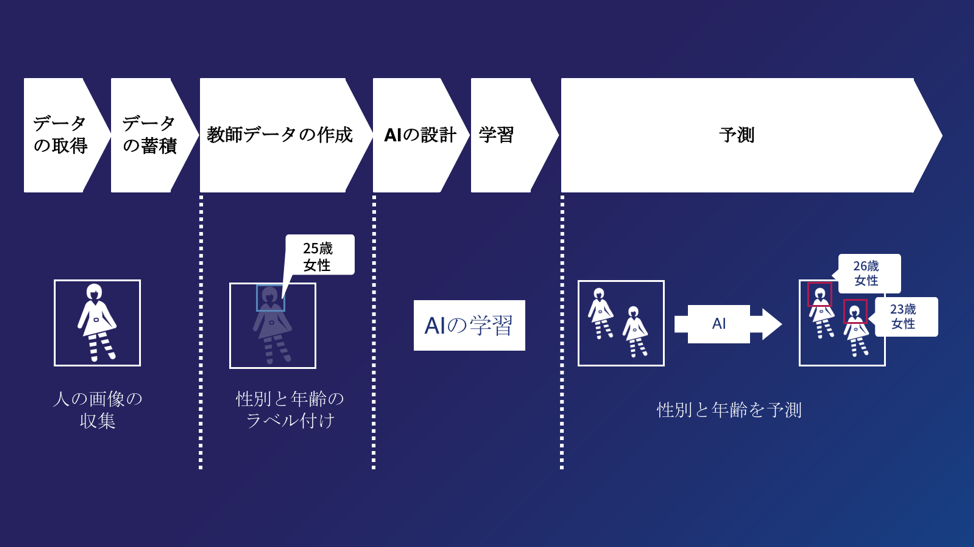
機械学習やDeep Learningの分野の手法を用いる場合、このようなデータが与えられた後、入力データから目標ラベルをより精度よく出力できる手法を考え、数式とアルゴリズムで表現することが一般的だ。
使用する数式やアルゴリズムが決まったら、「データからの学習」を行う。この「データからの学習」とは、入力データから目標ラベルをより良く出力することが出来るように、このアルゴリズムと数式内における調整可能なパラメーターを修正することを指す。
AIは魔法の杖ではない
そのため、例えば小売業において、来客人数の予測・人の性別の判別・人の年齢の推定などといった問題を解きたい場合、「データで学習していないこと」を実現することは基本的にはできない。
もちろん、様々な顔のデータで性別を予測する問題を学習させれば、新しい顔のデータが来た時に、性別を分類することはできる。しかし、「顔データから性別を学習したAI」は、同じ顔データであっても、「年齢を推定すること」はできない。また、もし入力データに日本人の顔データしかなかった場合には、日本人以外の顔データの場合には精度が低くなる可能性も含んでいる。
先述した例にあるように、一口に「顔のデータがある」と言っても、その顔のデータを使って何がやりたいか、そしてそのやりたいことに対して適切なラベルがデータに付いているか、が非常に重要である。
課題設定とデータの量・質が重要

これまで紹介してきたことが、昨今のAIブームの中心となっている機械学習、Deep Learningで出来ることの大きな枠組みである。
もちろん、これ以外にも入力データに対してラベルを付与することなく、データからその関係性を学習する「教師なし学習」と呼ばれるものや、AlphaGoなどで用いられた「強化学習」のような手法も存在する。教師なし学習で行われるものとしては、例えば店舗での購買実績をもとに顧客をカテゴライズしたり、お勧め商品をレコメンド(Recommendation)したりするものがあげられる。
これらの枠組みの中では、与えられた課題に対して、手法を決め、その手法内における調整可能なパラメーターをデータを元に修正することで、より精度が良い出力を出すように訓練する。
そのため、課題設定がそもそも既存のAIの枠組みで解くことができないようなものであったり、目的に沿う形でデータが整備されていなかったり、データ量が十分に集まっていなかったりした場合には、そもそもAIを活用することができない。よって、課題設定をうまく行い、質の良いデータを多く収集しておくことが、ビジネスにおいてAIを活用するあたってもっとも重要と言っても過言ではない。
逆に、課題設定が上手く出来ており、質の良いデータが十分にあれば、ビジネスに応用することができる。また大きなコスト削減や新たなビジネスチャンスの創出に起因するだろう。
次回は、実際に課題設定やデータの収集をうまく行い、ビジネスにおいて成功を収めた事例とそのポイントをいくつかの業界に渡って紹介する。








